Deep dive · Jump here anytime when you want more on this idea
Designing Autonomous Agent Teams
Multi-agent systems that coordinate on their own
After this, you'll be able to distinguish peer-to-peer coordination from hub-and-spoke orchestration, name the emergent failure modes that only appear at fleet scale, and decide when an autonomous team is the wrong choice.
Before you start
Complete Running Background Agents first; this lesson builds on the branch-per-agent isolation and cost-management patterns that peer-to-peer coordination extends.
The idea
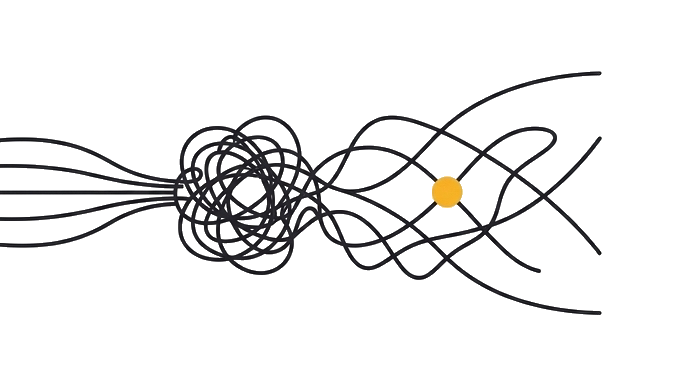
Level 10 removes the orchestrator bottleneck. At Level 9, one coordinator dispatches to workers and collects results. Level 10 is peer-to-peer: agents claim tasks from a shared store, pass findings directly to each other, and coordinate without a human relay. This is not an incremental improvement on Level 9. It is a different architecture with different failure modes.
- NoticeFind the moment where this lesson applies.
- Designing Autonomous Agent TeamsApply the lesson move to one real task.
- ProveMove on only when the check passes.
Be honest about what is and is not solved. True peer-to-peer coordination, where agents communicate directly without any shared coordinator, is still a research pattern in early 2026. Most real multi-agent setups that claim peer-to-peer are closer to distributed hub-and-spoke. The seams are visible. Nobody has fully solved reliability, recovery, and trust boundaries at production scale.
Here is the before and after: a team shipped a 'fully autonomous' 8-agent pipeline for content generation. On inspection, 6 of 8 agents still routed through a central Redis queue with a single coordinator process reading results. That coordinator was a hub. Calling it peer-to-peer was marketing. The actual peer exchange (2 agents passing structured data directly via shared memory) worked reliably. The other 6 connections did not. Honest architecture naming would have caught the design gap in week 1 instead of week 6.
The hard problem at Level 10 is emergent failures: failure modes that no individual agent would produce in isolation. Feedback loops. Conflicting writes. Resource starvation. A single agent making a bad decision is recoverable. A fleet of agents amplifying that decision at machine speed is not. Reproducibility is the first safety requirement. If you cannot replay a multi-agent run and get the same result, you cannot debug it.
Level 10 also means knowing when not to deploy an agent team. When a task requires nuanced judgment, irreversible actions, or domain expertise the model does not have, human review checkpoints are not overhead. They are the correct design. The goal is not maximum autonomy. It is maximum autonomy within the boundaries where correctness is machine-checkable.
Try it (5 min)
Watch out for
- Calling a system peer-to-peer because agents run in parallel. Parallel workers reporting to a shared queue is still hub-and-spoke. The pattern lives in the topology, not the concurrency.
- Removing the orchestrator before you have an observability replacement. Hub-and-spoke gives you one place to inspect status. Decentralize without that visibility layer and you cannot debug mid-run.
- Treating Level 10 as the reward for finishing Level 9. It is a tradeoff with new failure modes, not a promotion.
- Skipping reproducibility because the run worked once. A run you cannot replay is a run you cannot debug when it eventually fails.
Paste this into Claude
I am running a Level 9 multi-agent setup and considering moving toward Level 10 peer-to-peer coordination. Here is my current architecture: [describe how your supervisor dispatches to workers, what each worker does, and how results flow back]. Help me with three things. (1) Identify the single biggest bottleneck in my orchestrator: is it a throughput limit, a decision only the orchestrator can make, or a state synchronization problem? (2) Tell me whether removing the orchestrator would actually solve that bottleneck, or whether it would just relocate the problem. (3) If decentralization is justified, name one seam in my architecture that is genuinely safe to convert to peer-to-peer and one seam that must remain coordinator-gated, with a specific reason for each.
What good looks like
- You named the actual bottleneck in your current orchestrator with specific evidence, not a generic 'it is slow'
- You identified one seam safe for peer-to-peer coordination and one seam that must stay coordinator-gated, with reasons for each
- You can articulate in one sentence whether decentralization solves your bottleneck or just relocates it
When this breaks
- Breaks when peer-to-peer agents lack reproducibility because emergent failures cannot be debugged without replay, and an unreplayable multi-agent run is unrecoverable.
- Breaks when the task requires judgment, irreversibility, or domain expertise the model has not demonstrated because fleet-scale execution amplifies a single bad decision faster than a human can intervene.
- Breaks when teams confuse marketing-grade decentralization with actual peer-to-peer because the visible seams (a Redis queue, a coordinator process) silently re-introduce the bottleneck the architecture was supposed to remove.
AI can help with this
Use AI to apply this lesson to your current work. Share your situation, ask for one concrete next step, and check the answer against this test: Identify in your current Level 9 architecture which single seam, if any, is genuinely safe to convert to peer-to-peer and explain why the other seams must stay coordinator-gated.
You can now
Identify in your current Level 9 architecture which single seam, if any, is genuinely safe to convert to peer-to-peer and explain why the other seams must stay coordinator-gated.
Key takeaways
Level 10 is peer-to-peer coordination without a hub. The hard problem is emergent failures the fleet creates that no single agent would, and the discipline is knowing when not to deploy autonomy.
- Level 10 is peer-to-peer coordination without a hub orchestrator. It is a different architecture, not just more agents
- Emergent failures are the hard problem: fleets amplify mistakes that individual agents would not make alone
- Reproducibility is the first safety requirement. If you cannot replay a run, you cannot debug it
- Human checkpoints on irreversible or judgment-dependent tasks are correct design, not a sign of failure.